Sanskrit Unicode Text Processing
This document describes how to get your GNU Emacs and LaTeX configured for processing Sanskrit in Unicode. The assumption is that you already have a recent Linux distribution with Emacs, Mule and LaTeX/teTeX installed. A list of all the required packages is given below.
The development of Unicode as a standard for multilingual text processing means that current non-unicode compatible methods for inputting Sanskrit (and other Indian languages) could become obsolete in the near future. For those currently editing Sanskrit texts or using Sanskrit diacritics in their written work, this means that compatibility could become an issue as publishers adopt the new standard.
There are more than a dozen current solutions for Sanskrit text processing, from such ancillary packages as Frans Velthuis's Devanāgarī for Tex to Avinash Chopde's Itrans system for Indian Languages and his more simple online conversion utilities. With few exceptions, most solutions are platform specific and built around a certain coding method that in most cases requires its own set of compatible fonts. Examples in this category are Devakey by Peter Haunert, Itranslator from Omkarananda Ashram and John Smith's Indic fonts and tools based on the csx+ standard (Classical Sanskrit Extended plus) adopted by many scholars after the 8th World Sanskrit Conference in Vienna. A more detailed list of text processing tools and fonts for Indian languages can be found on the Indology site maintained by Dominik Wujastyk.
Although a few Unicode text processing solutions for Sanskrit have become available, such as the tiny Takhti editor for Devanāgarī and Gaspar Sinai's versatile Yudit (supporting most Asian languages), they usually limit the user to a particular platform and an editor with very rudimentary functionality.
1. utf-skt for Emacs and LaTeX
One of the most satisfactory solutions for Sanskrit Unicode support is the utf-skt package. The package contains a Sanskrit input scheme for Emacs, and corresponding translation methods for Tex.
I have successfully installed and tested the utf-skt package on a Linux machine running Mandrake 9.0, and on a PowerBooK G4 laptop running OS X 10.3x, but it should work well under all recent distributions of Linux and OS X. Windows and Macintosh versions of Emacs and LaTeX are also available and in principle the package should work on those platforms as well since most of its components are platform independent.
The package is available for download from Jürgen Hanneder's page, along with a generic description of installation and configuration procedures for your environment. Stefan Baums, the author of one of the main components has also put together a short description on using Emacs and Tex for Sanskrit romanized typesetting and has copies of sanskrit.el and sanskrit.ocp for download.
I wish to acknowledge their contribution as well as those of Toru Tomabechi and John Smith for the development of the other components in the package. In what follows, I give a brief description of all my installation and configuration steps.
2. Requirements
An up and running recent distribution of Linux it's all you really need. However, if you are new to Linux and did an automatic or default install, some packages may be missing. Make sure you have Emacs mule, mule-ucs and teTeX installed. Listed below are the mininum requirements:
- GNU Emacs with Mule/XEmacs and mule-ucs (20.1 and above)
- Omega LaTeX (teTeX)
- XFree86 with at least one Unicode font package installed (XFree86 Version 4.0 and above comes with unicode support by default)
- and the utf-skt package
The description that follows refers to my own system which is a Mandrake 9.0 (kernel 2.4.19) running on a Dell Inspiron 2100 laptop. The rest is as follows:
- GNU Emacs 21.2.1 (with mule and mule-ucs)
- Omega teTex
- XFree86 Version 4.2.1
- the utf-skt package
Because the installation procedure requires that you update files that are not in your $HOME path, this also assumes that you have root or sudo privileges. You may have to ask you local system administrator for support if you only have limited user access to your Linux machine.
3. Installation
Assuming that you have all the other packages listed above, go to the directory where you saved the utf-skt tar ball and unpack it. This creates a directory utf-skt/ containing the subdirectories texmf/ and user/. Copy the files in the subdirectory texmf/ to the appropriate locations in the texmf/ path on your system. Do not forget to run texhash to update the TeX files index. The directory user/ contains examples and the sanskrit.el file. Copy the sanskrit.el file to your Emacs Leim path. In my case I had to copy it to:
%> cp ~/sanskrit.el /usr/share/emacs/21.12/leim/
4. Emacs Configuration
The sanskrit.el adds emacs lisp support for Sanskrit. Emacs can read both the emacs lisp (*.el) file and its byte‐compiled (*.elc) version. To compile it, start emacs and byte-compile sanskrit.el. Usually you do this by issuing in the mini-buffer the commands:
C-x C-f to reach the Emacs leim path where you copied the sanskrit.el file and execute:
M-x byte-compile-file sanskrit.el
This creates a sanskrit.elc file in the same directory.
Now it is necessary that you inform Emacs about the new input method. There are several options here (see Hanneder and Baums). My own solution involved editing the leim-list.el usually found in /usr/share/emacs/(version)/ and registering the new input method. Open leim-list.el and insert the following string anywhere in the language method list:
(register-input-method "sanskrit" "Sanskrit" 'quail-use-package' "SANt" "Sanskrit Transliteration input method" "quail/sanskrit")
That is all you need to do. No additional specification in your .emacs file is necessary. You can now start Emacs and use C-x RET C-\ to select input method, choose Sanskrit and you can begin typing romanized Devanāgarī. For all underdot characters you type "." followed by the character (ex: .m to get ṃ). For the accented ones type "#" followed by the character (ex: #a to get ā). To view the input table while typing use C-h I
Now you no longer need to type in the odd TeX commands Devan\={a}gar\={\i} to get Devanāgarī. Here are a few verses from Dharmakīrti's Pramāṇavārttikam in my Emacs. You can also download the sample.txt that you see below.
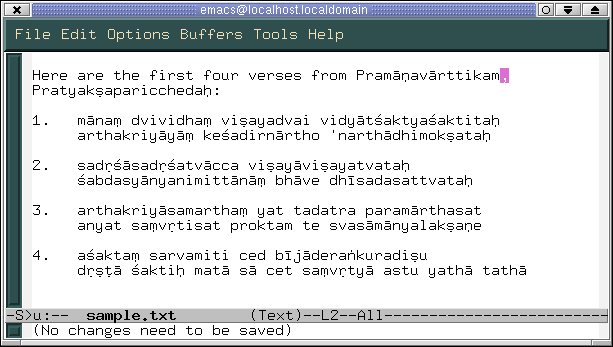
It is likely that you will be using more than one language in you document. For multilingual text processing with Emacs see the documentation on Mule. In general, if Mule is correctly configured all you need to do is switch between input methods with C-x RET C-\ to select your input language. Always remember to save you document in utf-8.
5. Typesetting Sanskrit documents under LaTeX
For printing and document layout you can now use the Omega package with the following commands at the top of your LaTeX file:
\documentclass[oneside,onecolumn,12pt,a4paper]{article}
\usepackage{times}
\usepackage{ucs}
\usepackage{fullpage}
\usepackage[utf8]{inputenc}
\usepackage{times}
\usepackage{fancyhdr}
\begin{document}
Here is the first verse from Pramāṇavārttikam, Pratyakṣaparicchedaḥ:
mānaṃ dvividhaṃ viṣayadvai vidyñtñaktyaśaktitaḥ
arthakriyāyāṃ keśadirnārtho 'narthādhimokṣataḥ
\end{document}
or alternatively, the commands for Omega tex as shown below
\ocp\InUTF=inutf8
\DefaultInputTranslation onebyte \InUTF
\InputTranslation currentfile \InUTF
\documentclass{article}
\ocp\Sanskrit=sanskrit
\ocplist\MyOCPList=
\addbeforeocplist 1 \Sanskrit
\nullocplist
\pushocplist\MyOCPList
\begin{document}
Here is the first verse from Pramāṇavārttikam, Pratyakṣaparicchedaḥ:
mānaṃ dvividhaṃ viṣayadvai vidyñtñaktyaśaktitaḥ
arthakriyāyāṃ keśadirnārtho 'narthādhimokṣataḥ
\end{document}
For typesetting Devanāgarī see further information on Jürgen Hanneder's page. To view an input Tex file download sample.tex and open it in Emacs or any other unicode compatible editor.
Here is the sample.dvi output that you see below after running lambda.
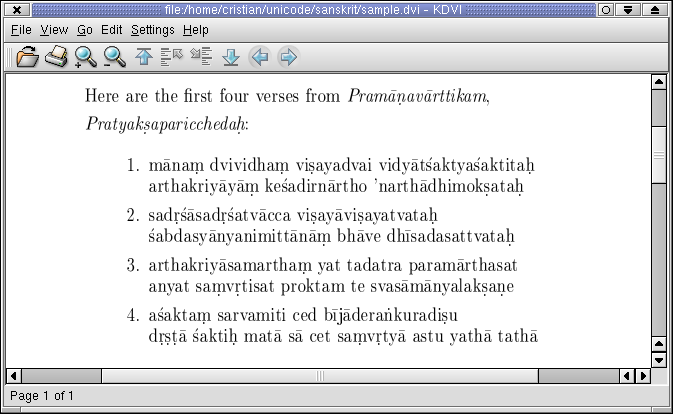
If you have installed the ps2pdf and dvipdf utilities you should be able to generate your pdf file from within your DVI viewer. Alternatively you can generate a PostScript file and run ps2pdfwr for pdf output. Here is my sample.pdf file.
If you have not selected your coding method while processing text in Emacs, when you save the file you will be prompted to choose a safe method. Choose one of the compatible utf-8 and its variants. Otherwise, Emacs will use its own translation methods. In general it is safer to select your coding system before opening a new file and also select the input method. For example
M-x prefer-coding-system and select utf-8
followed by C-x RET C-\ and select sanskrit as your input method.
You can also save your documents as html and publish them online directly. You will need to specify the charset utf-8 in you html document header. For example:
<meta http-equiv="Content-Type" content="text/html; charset=utf-8">No additional embedded fonts are necessary. Any browser with unicode support enabled should correctly display your romanized Devanāgarī in various typefaces (Ex: Devanāgarī, Devanāgarī, Devanāgarī).
Christian Coseru College of Charleston Department of Philosophy coseruc AT cofc DOT edu
![]()